

William Poole speaking at his EPS graduation ceremony in 2009.
Computational Complexity In Biology
By William Poole, Eastside Prep Class of 2009
AS AN EPS GRADUATE AND FORMER EPS MATH teacher, now working toward my PhD in Computation and Neural Systems at Caltech, I hope you will find the following article educational and get a taste of how computer scientists are influencing scientific thinking in biology. Eastside Prep without a doubt fostered the interdisciplinary mindset and thrill of learning that has sustained me on the very long road of an incredibly multifaceted PhD.
 Theoretical computer scientists frequently try to understand the difficulty of a problem and ask what kinds of computing devices can solve it. One way to do this is by showing that two models of computation (loosely, two different kinds of computers) are equivalent. In order to reason this way about computability, Alan Turing invented a model of computation called a Turing machine, illustrated in Figure 1. The Church-Turing thesis provided examples of computational universality, showing that many models of computation are equivalent if they can solve the same classes of problems in similar amounts of time. In modern computer science, it is known that all non-quantum computers are universal with respect to each other and with respect to a Turing machine. Computational universality is a very powerful idea—it allows computer scientists to think in terms of simple models of computation (such as Turing machines) in order to reason about problems instead of dealing with all the physical details of a real computer.
Theoretical computer scientists frequently try to understand the difficulty of a problem and ask what kinds of computing devices can solve it. One way to do this is by showing that two models of computation (loosely, two different kinds of computers) are equivalent. In order to reason this way about computability, Alan Turing invented a model of computation called a Turing machine, illustrated in Figure 1. The Church-Turing thesis provided examples of computational universality, showing that many models of computation are equivalent if they can solve the same classes of problems in similar amounts of time. In modern computer science, it is known that all non-quantum computers are universal with respect to each other and with respect to a Turing machine. Computational universality is a very powerful idea—it allows computer scientists to think in terms of simple models of computation (such as Turing machines) in order to reason about problems instead of dealing with all the physical details of a real computer.
A natural question then arises: What kinds of computations is molecular biology capable of? To tackle this problem, we first need an idealized model of how computation could occur in a biological system. One such model is called a polymer reaction network. These networks consist of chemical species and reactions which should look familiar from high school chemistry class. For example A+C → B+C is a catalytic reaction when some catalyst, C, converts species A into species B. We will also allow for reactions involving polymers. A polymer is a molecule made up of a sequence of sub-molecules, called monomers. Polymers are ubiquitous in biology. For example, DNA is a polymer made up of four nucleotide bases which are repeated to form the genetic code, proteins are polymers made up of sequences of amino acids, muscle fibers are polymers of actin crosslinked by myosin motors, etc. A polymer reaction is just like a normal chemical reaction, but with additional information about the polymer sequence. For example, a small sequence of your genetic code might dictate which regulator proteins bind to it. (More examples of polymer reactions are given in Table 1.)
The fact that biologists have had so much success decoding the molecular underpinnings of life attests to their incredible ingenuity and perseverance.
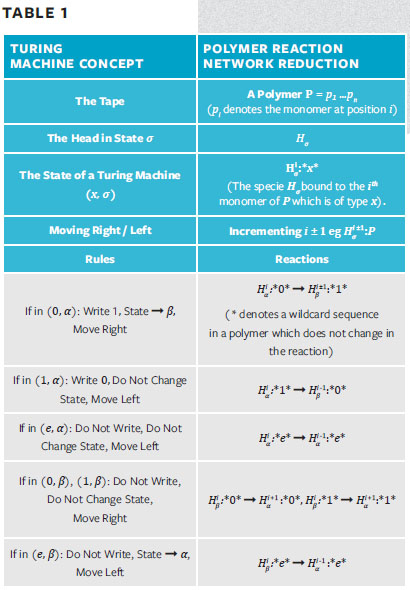 In Table 1, I have written down a polymer reaction network which is equivalent to the Turing machine described in Figure 1. This illustrates one of the key methods, called reductions, that computer scientists use when studying complexity. In a reduction, one system is shown to reduce to another system. I have informally reduced a Turing machine to a polymer reaction network, which means that polymer reaction networks must be at least as computationally powerful as Turing machines. Moreover, I also know how to simulate a polymer reaction network on my laptop, which is equivalent to a Turing machine due to the Church-Turing thesis. Therefore, Turing machines are also at least as powerful as polymer reaction networks. If Turing machines and polymer reaction networks are mutually “at least as powerful as the other,” they must be computationally equivalent. This statement has large ramifications for molecular biology: it means that a cell, in theory, could do anything a computer could do, which is a lot! Indeed, the fact that biologists have had so much success decoding the molecular underpinnings of life attests to their incredible ingenuity and perseverance.
In Table 1, I have written down a polymer reaction network which is equivalent to the Turing machine described in Figure 1. This illustrates one of the key methods, called reductions, that computer scientists use when studying complexity. In a reduction, one system is shown to reduce to another system. I have informally reduced a Turing machine to a polymer reaction network, which means that polymer reaction networks must be at least as computationally powerful as Turing machines. Moreover, I also know how to simulate a polymer reaction network on my laptop, which is equivalent to a Turing machine due to the Church-Turing thesis. Therefore, Turing machines are also at least as powerful as polymer reaction networks. If Turing machines and polymer reaction networks are mutually “at least as powerful as the other,” they must be computationally equivalent. This statement has large ramifications for molecular biology: it means that a cell, in theory, could do anything a computer could do, which is a lot! Indeed, the fact that biologists have had so much success decoding the molecular underpinnings of life attests to their incredible ingenuity and perseverance.
In my personal research, I try to relate machine learning algorithms such as deep neural networks to the biological networks of interacting molecules inside of cells.
Those of you who remember any cellular biology from high school or college are probably already quibbling with my informal proof: the polymer reaction network you defined doesn’t look anything like the central dogma of biology, where DNA is transcribed into RNA, which in turn is translated into proteins. And I would agree with you—the notion of computational universality is abstract and tries to put limits on what is theoretically possible, without saying this is how a given model of computation should be physically coded. In the case of molecular biology, a Turing machine is probably not the most natural model for how biology works. In my personal research, I try to relate machine learning algorithms such as deep neural networks to the biological networks of interacting molecules inside of cells. The hope is that the mathematics underlying machine learning can lead to clearer and more quantitative models of how biology physically functions and can connect these models easily to data.
My field, the intersection of computer science, engineering, and biology (often called synthetic biology or molecular programming) has made huge strides in the past two decades in harnessing the engineering and theoretical framework that underlies computer science and modern engineering in order to build scalable and programmable biological systems. I believe that we are on the verge of a synthetic biology revolution where we will be able to program living organisms for an untold number of medical and industrial applications. This could lead to a world where we program plants to produce chemicals instead of using industrial factories, where every part of our infrastructure is interfaced with living organisms, where we can kill cancer by reprogramming the very cells that cause it. However, like any paradigm-shifting technology, there will be risks. We need an engaged public and well-informed politicians to debate and implement intelligent regulation. We need scientists and funding agencies with strong ethical guidelines. We need international treaties to manage and mitigate weaponization of these technologies.
So what can EPS do to prepare students for the huge technological changes and societal repercussions which are likely coming in our lifetimes? Well, a simple answer is: keep up the stellar work! By teaching students to learn independently, think innovatively, and break the bounds of traditional disciplines, EPS already does an excellent job preparing its students for diverse workplaces and an unpredictable future.
 About the Author
About the Author
William Poole is a member of Eastside Prep’s first graduating class—the Class of 2009. William attended Brown University and is currently working towards a PhD at Caltech. For this issue of Inspire, William writes about his field of study and his year teaching at EPS.